Ralph Sarkis
{kind=link}
I am a postdoctoral fellow in computer science at PPLV (University College London). I did a PhD in theoretical computer science at LIP (ENS de Lyon), supervised by Matteo Mio and Valeria Vignudelli. I also have a masters in theoretical computer science from ENS de Lyon and a B.Sc. in Mathematics and Computer Science from McGill University. My main interests are category theory, theory of computation and logic. I have been keeping a sparse journal of my professional activities here. My non-academic interests include but are not limited to playing squash, vegan cooking, programming (Python and JavaScript mostly), watching YouTube, and playing Spikeball.
Contact: msg@firstname.lastname.cc CV: English, Français Pronouns: he/him
Publications
Conference Proceedings
- Combining Nondeterminism, Probability, and Termination: Equational and Metric Reasoning (with Matteo Mio and Valeria Vignudelli) [LICS 2021][arXiv][YouTube]
- Semialgebras and Weak Distributive Laws (with Daniela Petrişan) [MFPS 2021] [arXiv][HAL][Video]
- Beyond Nonexpansive Operations in Quantitative Algebraic Reasoning (with Matteo Mio and Valeria Vignudelli) [LICS 2022][arXiv]
- String Diagrams for Graded Monoidal Theories with an Application to Imprecise Probability (with Fabio Zanasi) [CALCO 2025][arXiv]
- Quantitative Monoidal Algebra: Axiomatising Distance with String Diagrams (with Gabriele Lobbia, Wojciech Różowski, and Fabio Zanasi) [MFCS 2025] [arXiv]
- Complete Diagrammatic Axiomatisations of Relative Entropy (with Fabio Zanasi) [MFPS'26][arXiv]
Journals
Ongoing Projects
Category Theory Lectures
I have written and am constantly updating a set of lecture notes for an introductory category theory course aimed at undergraduate students. I am currently compiling them in a book format.
Links :
Becoming a Professor
My primary career goal is to become a professor in a computer science or mathematics department of a university.
- In 2024/25, I applied to Lecturer positions at Imperial College, McGill, Polytech Saclay (MCF within LMF), and Queen Mary. Among other things, I submitted a cover letter, a teaching statement, a teaching dossier, an equity, diversity, and inclusion (EDI) statement, a rapport d'activités, and a présentation analytique. For a 15 minutes interview at Polytech Saclay, I prepared these slides.
- In 2025/26, I applied to a professor position at UdeM and to the CNRS CRCN competition. Among other things, I submitted a lettre de motivation, a dossier d'enseignement, a rapport sur les travaux antérieurs, and a projet de recherche.
Older Projects
PhD Thesis
I defended my thesis entitled Lifting Algebraic Reasoning to Generalized Metric Spaces in September 2024 at ENS de Lyon. It was supervised by Matteo Mio and Valeria Vignudelli. Here are the slides of the defense.
ACT Adjoint School 2022
I was part of the 2022 edition of the ACT Adjoint School working on the project supervised by Filippo Bonchi.
Links :
Talk on Diagrammatic Languages
I gave a 15 minute talk for a general audience on diagrammatic languages in mathematics as part of the Café Gourmand et Scientifique at LIP. I extended this talk with a small demo for the McGill grad seminar.
Links :
Semantics and Verification Lecture Notes (Winter 2020)
During the Winter 2020 term, I have typed lecture notes for Semantics and Verification taught by Colin Riba.
Links :
Higher Algebra 2 Lecture Notes (Winter 2019)
During the Winter 2019 term, I have typed lecture notes for Higher Algebra 2 taught by Henri Darmon. David Marcil has also proofread and completed a few parts of the notes.
Links :
SUMM 2019 Conference
I gave a 45 minute talk at SUMM in January 2019 introducing the P vs. NP problem.
Links :
Lecture Notes for Fall 2018
I compiled a study document for the content covered in Higher Algebra 1 taught by Eyal Goren in Fall 2018 and I typed up lecture notes for the first section of a course on Combinatorial Optimization taught by Bruce Reed.
Links :
Category Theory Study Group (Summer 2018)
In the summer term of 2018, I organized a reading group on category theory with a few friends, we followed the lecture notes of Mariusz Wodzicki and tried to produce our own set of notes. The goal of this project was to get familiar with basic category theory concepts.
Links :
SUMM 2018 Conference
I gave a 35 minute talk at SUMM in January 2018 introducing some concepts in machine learning.
Links :
Graph Theory Lecture Notes (Fall 2017)
I typed up lecture notes for my MATH 350 class given by Jan Volec.
Links :
Study Documents (Fall 2017)
I compiled study documents for MATH 456 taught by Eyal Goren, MATH 356 taught by Linan Chen and MATH 350 taught by Jan Volec.
Links :
Cryptocurrency Browser Extension (Summer 2017)
While I was learning about cryptocurrencies, I decided to code a browser extension that can display the balance in your cryptocurrency wallets.
Links :
Web Games (Summer 2016)
I have coded a few interesting web games while learning JavaScript.
Links :
Fractal Design (Winter 2015)
I have designed a website to present a fractal design project for my calculus 2 class given by Patrick St-Amant.
Links :
Project Euler (Fall 2015)
While I was learning Python, I solved the first 50 problems from Project Euler.
Links :
Resources I Use
Friends and Collaborators
By far, my most reliable and effective resource is the set of friends and collaborators I was lucky to meet. Here is a non-exhaustive enumeration of them.
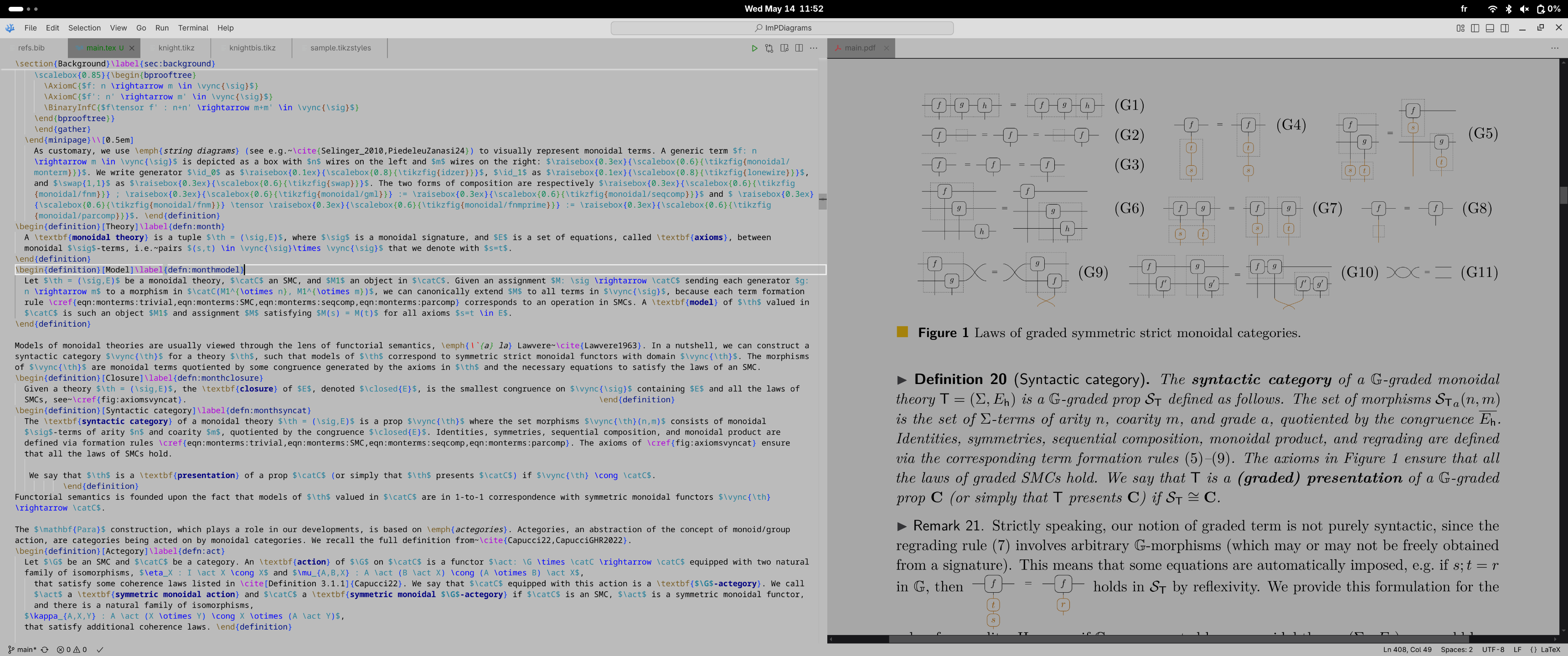
For Typesetting
My current setup is VSCodium as an IDE and pdf viewer. Most of the time, my screen looks like this. I use this script (which relies on this solution) to change the background color of the integrated pdf viewer.
{kind=link}
Links :
Miscellaneous
For Nonmathematicians
As you might have inferred from the rest of my website, I really enjoy teaching. Unfortunately, my day-to-day activities involve too many levels of abstraction for me to easily describe them to nonexperts. Thanks to years of practice, I was able to find very good (in my opinion) answers to the question "What do you study?" that help my family and friends better understand what I do. Here are the best relatively short and simple explanations I could come up with to describe my favorite fields of study (in no particular order).
Complexity Theory
This one is heavily inspired from examples in Giorgi Japaridze's Introduction to Computability Logic.
The main goal of complexity theory is to answer the question "What makes a problem hard or easy to solve with a computer?". Of course, there are many angles to attack this question, for example, one needs to define what is a computer, what is a problem, and what it means for a problem to be hard or easy. I will save these discussions for later and only demonstrate the difficulty in answering this question. Let me describe three different tasks varying in complexity.
Your first task is to win at chess against the best artificial intelligence designed to optimally play chess. To make this easier on you, you can control the white pieces (you play first) and it is considered a win for you if the game resolves in a stalemate (tie). You probably know that this is almost impossible to do; all grandmasters of chess (the best human players) cannot compete even with AI players built decades ago.
Your second task is to play two games of chess against the best AI and win (or tie) on at least one board. To make it slightly fairer, in your first game, you control the white pieces, and in your second game, you control the black pieces. I will let you convince yourself that the second task is harder than the first one because the latter is included in the former. Namely, to complete the second task, you must win at chess against the AI and hence complete the first task.
Your third task is to play two games of chess simultaneously against the best AI and win (or tie) on at least one board. Again, there is a board where you play whites and a board where you play blacks. At first sight, this task may look harder than the first one (because you are playing on two boards at once) and just as hard as the second one. In any case, this should still be hopeless.
Surprisingly, the third task is the easiest to complete and anyone could do it after being told the strategy. You simply have to copy the moves done by the AI on one board on the other board. That is, you let the AI play its first move on the board where it plays whites and you do the same move on the board where you play whites, then you wait for the AI's answer to that move and you replicate it on the other board. Whatever happens during the game, if the AI wins (or ties) on one board, you automatically win (or tie) on the other board, thus you complete the task.
It is very fascinating to me (and I guess to most complexity theorists) how these three tasks with a very similar description have very different intrinsic difficulties. To rephrase the ultimate goal of complexity theory, it would be wonderful if we could tell how hard it is to solve a problem by looking only at its statement.
As I have mentioned, there is a lot more to complexity theory that was not advertised in this toy example. Still, I hope this makes you wonder more deeply about the original question as many computer scientists do every day.
Semantics
My main field of research is called categorical semantics. I have yet to come up with a quick layman explanation for the term 'categorical', but I think I can give you the gist of what studying the semantics of programming languages means.
It is infamously hard to predict the result of executing a computer program by looking at its code. Of course, humans (with programming experience) are exceptionally good at this task; if you ask a programmer to look at some simple code written by another human, they will surely be able to describe what it does. However, this takes time and as the code gets longer and more complex, humans are more likely to make mistakes. This is the main reason why bugs exist — ironically, the origin of the word "bug" suggests that the error is not the programmer's fault. The principal objective of program semantics is to help design programs that can understand how other programs behave by looking at their code.
The term semantics comes from a central step in the analysis of programs where we give meaning to each part of the code before bringing it together into information about the whole program. The details vary wildly depending on the method used, how the program is specified (e.g. what programming language), and the properties of the program that are considered. Anyway, you can basically think of this step as a translation of the code into abstract mathematical objects which themselves have to be interpreted to understand the result.
Let me use a cooking analogy to give more intuition about the process described above. It is also hard to predict the result of a recipe without following its every step. This time, even a human (with cooking experience) will have a hard time being able to tell with good accuracy what the end result is supposed to look like, if it will taste good to them, etc. — I concede that a very good chef who has seen similar recipes before will fare better, but if they have never seen how, say, puff pastry is made, I doubt they can foresee the transformation from layers of dough and butter into flaky, crusty and light pastries.
One could imagine a program that reads a recipe and generates the outcome of each step as a sequence of chemical reactions (these replace the abstract mathematical objects in the programming story) that will happen during the cooking. The program could then extract some useful information to tell us whether there is too much compounds that taste like burnt food, there is not enough chocolate flavor compounds, the Maillard reaction has produced enough brown color, enough water evaporated to get a crispy crust, and so on...
It is hard to say with certainty which of analyzing code or recipes is easiest (see my explanation of complexity theory), but I would certainly love it if we are able to do either in my lifetime.
Hodgepodge of Ideas
Here are hand-picked ideas (they maximize some function depending on originality and potential) from my much longer list of ideas.
Crowdsourcing YouTube Captions in Class
I would like to build a platform where language teachers can give as homework to their students the task of captioning YouTube videos. Initially, the teacher can assemble a big playlist with videos in their desired language which have no captioning yet (or maybe the video has caption in one language but not in another). Then they can ask their students to choose a video in this playlist and caption it (or translate the existing captions). Finally, the teacher can go over the work done by the students and correct it before submitting the captions to YouTube.
I think that many people (teachers, creators, and students) could benefit from a platform like this. I trust the great diversity in the content published to YouTube will make it possible for every teacher to find videos they think are suitable for their class and for every student to find a video they can engage with. The creators will also reach a larger audience through this platform.
I am also pretty sure this could easily be implemented as part of Google Classroom. As of November 2020, I have not found such a project and even worse, YouTube has recently removed the community contributions.
Restaurants Sharing Recipe Videos
I always wonder how the food I order at restaurants is made, and I am sure I am not alone. While scrolling through social media, I often come across videos of people making beautiful food, and it makes me hungry. Sharing the process of cooking a dish in a video or gif format could be an excellent way for restaurants to attract more customers. Many people choose restaurants by looking at online menus, and having videos of the dishes being made would provide an added level of appeal.
To make this possible, restaurants could hire video producers to create videos of their dishes being made. These videos could be shared on the restaurant's menu or on already existing platforms such as social media, reviews agregators (e.g. Google Maps), making it easier for customers to discover and choose a restaurant. While producing these videos may require some investment, it could be a worthwhile way for restaurants to stand out and attract more customers. Additionally, it could provide an opportunity for aspiring video producers to work with restaurants and showcase their skills.
I believe that creating a good website for a restaurant can be challenging, especially if they need to incorporate videos. That is where my second idea comes in: creating a template for a restaurant website that includes the option to display videos of their dishes being made. I don't know how to best display menu items and the videos of them being made to get a seamless way for customers (especially on mobile), I am sure a UI/UX designer will find this a fascinating challenge.
No Rights Reserved
The following is a copy & paste from Toby Bartels' page, but it applies to me as well.
I maintain no copyright or patent restrictions on any of my creative work. As far as copyright and patent law are concerned, I grant you irrevocable permission to do anything with my work that you wish. This is a perfectly free, noncopyleft licence. For example, you may:
- redistribute the work;
- create and distribute a derivative work;
- translate the work and distribute the translation;
- edit the work and distribute the edited version;
- combine the work with other works and distribute the result;
- aggregate the work in a distribution with other works;
- charge whatever the market will bear for the above.
Some of the creative work that I produce is a modification derived from other persons' previous work. Since the other persons may reserve legal rights to their work, you might not have legal permission to do what you want with my work, even as far as copyright and patent law are concerned. But that could only be because you did not have permission from the other persons; you already have permission from me.
I request that you give me credit for my work, and that you offer any derivative works and so forth to other people with no conditions, as I have offered this work to you with no conditions. But I will not enforce these requests legally; they are not requirements. You will have to decide for yourself.